
저번까지 로컬 환경에서 DynamoDB로 접근할 수 있도록 IAM 권한 설정을 하였다.
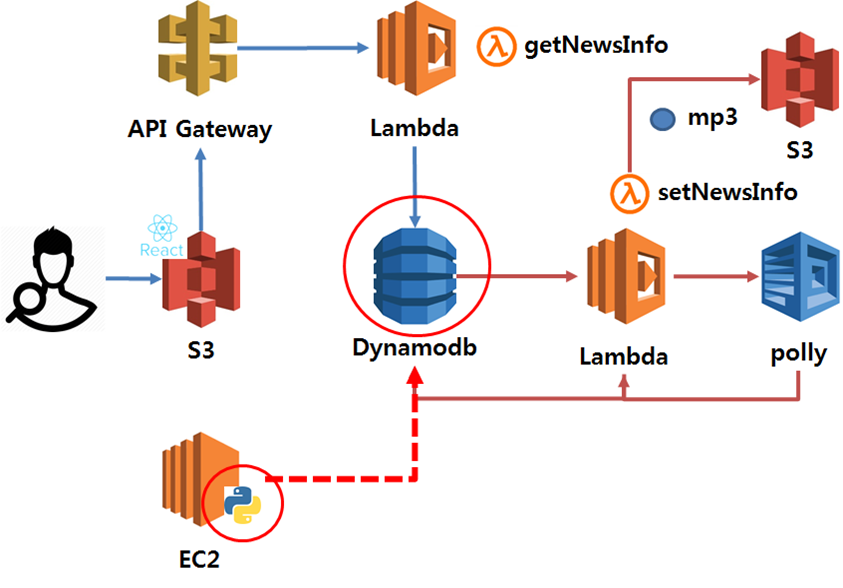
이번에는 로컬 환경에서 DynamoDB로 Insert 할 수 있는 Python 예제 프로그램을 작성하도록 하겠다. 위 사진으로 본다면 EC2에서 DynamoDB로 접근하는 프로세스이다. 참고로 본인의 로컬 환경은 Window7 OS 환경에서 개발을 진행한다. 그리고 개발 툴(IDE)은 python 기본 IDE인 IDLE을 사용한다. 개발 툴(IDE)은 본인이 원하는 다른 툴을 사용해도 된다. 난 그냥 IDLE를 사용한다. 왜냐면 개인적으로 멋있다. 약간 C 프로그래밍 할 때 vi 같은 느낌이라 할까? anyway...
Python을 설치를 하고 아래의 라이브러리들을 설치한다. Window cmd창을 열고 아래의 명령을 친다. 당연히 아래의 pip, pip3 명령어를 사용하기전 OS 환경변수에 pip, pip3를 사용할 수 있도록 설정한다.
requests 라이브러리를 설치한다.
pip install requests다음 beautifulsoup4 라이브러리를 설치한다.
pip3 install beautifulsoup4다음으로는 AWS DynamonDB에 Python 언어로 접근하기 위해서는 boto3가 설치 되어야 한다. 따라서 boto3 라이브러리를 설치한다. (각 언어마다 AWS 서비스를 사용하는 방법은 다른다.)
pip install boto마지막으로 json 문자열을 사용을 위해서 json 라이브러리를 설치한다.
pip install jsonPython IDLE를 열고 아래의 소스를 작성한다. 크롤링을 한 후 데이터는 본인이 원하는 대로 가공하면 된다. 문자열 처리 방법은 인터넷에 검색해보면 많이 나온다.
참고로 크롤링을 하면서 느낀점은 jquery의 Selector 개념을 알고 있으면 크롤링을 정말 쉽게 접근 할 수 있다는 생각이 들었다.
#!/usr/bin/python
import requests
import boto3
import json
from bs4 import BeautifulSoup
class Craw:
def getCrawling(self):
# Referer는 사용해도 되고 안해도된다.
# 그러나, Referer값을 활용하여 비정상적으로 URL 접근을 하는지 판단하는
# 사이트가 있으므로 가능하면 넣어주자
request_headers = {
'User-Agent': ('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'),
'Referer': ''
}
# 1365 게시물을 크롤링한다.
get_params = []
get_params.append('1365')
# 1365 게시물을 크롤링한 후 DynamoDB에 적재를 하도록 데이터를 정재한다.
for idx, param in enumerate(get_params):
print('======== index : {} param : {} ========'.format(idx, param))
# 본인이 크롤링하고자 하는 사이트의 URL를 넣는다.
response = requests.get('http://www.sample.co.kr/selectReg.do?idxno=' + param)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 크롤링을 할 때는 jquery의 Selector 개념을 알고 있으면 많은 도움이 된다.
##### 뉴스 제목 가져오기 #####
news_subject = (soup.select('header.article-header-wrap')[0]).text
print('뉴스 제목 \n{}'.format(news_subject))
##### 뉴스 내용 가져오기 #####
news_desc = ''
for tag in soup.select('#article-view-content-div p'):
news_desc += tag.text
print('뉴스 내용 \n{}'.format(news_desc))
##### 뉴스 날짜 가져오기 #####
date_time = (soup.select('section.article-head-info div.info-text li')[1]).text
print('날짜 및 시간 \n{}'.format(date_time))
insert_data = {
'REG_DT' : date_time,
'REG_SRNO' : idx + 1,
'SUBJECT' : news_subject,
'CONTENT' : news_desc
}
# DynamoDB Insert 함수 호출
self.insertNewsData(insert_data)
def insertNewsData(self, data):
# DynamoDB 접속 및 put_item 실행
try:
dynamodb = boto3.resource('dynamodb', region_name='리전명')
table = dynamodb.Table('DynamoDB 테이블명')
response = table.put_item(Item = data)
print('putItem successed!!')
print(json.dumps(response))
except ValueError as err:
print(err)
if __name__ == '__main__':
newCraw = Craw()
newCraw.getCrawling()마지막으로 insertNewsData 함수에서 데이터를 Insert 한다. 참고로 예제 소스라서 함수 호출할 때마다 DB에 접속하도록 했다. 실제로는 __init__ 함수에서 DynamoDB의 접속한 객체를 설정하고 재사용해야 한다. 아무튼 이 부분은 이후의 작업이다.
Insert 된 데이터 확인은 아래와 같이 확인을 하면 된다.
- AWS 콘솔창 접속
- DynamoDB 섹션으로 이동
- 좌측 메뉴 테이블 클릭
- 내가 생성한 테이블 클릭
- 우측 탭에서 [항목] 탭 클릭

위와 같이 Insert 된 데이터가 확인되면 성공한 것이다. 처음에는 엄청 자랑스러웠는데 지금은 무덤덤하다.
다음에는 DynamoDB에 위의 데이터가 적재가 되면은 polly에서 TTS 처리 후 mp3가 S3로 적재되는 부분까지 진행하도록 하겠다.
※ DynamoDB 로컬 버전도 존재한다. AWS까지 접속하지 않고 DynamoDB를 로컬에 설치 후 테스트 해볼 수도 있다.
'관심분야 > 클라우드' 카테고리의 다른 글
| #6 Lambda Function 작성 - AWS 음성지원 서비스를 활용한 신문 읽어주는 프로젝트 (0) | 2019.11.23 |
|---|---|
| #5 DynamoDB, Lambda Trigger 연결 - AWS 음성지원 서비스를 활용한 신문 읽어주는 프로젝트 (0) | 2019.11.23 |
| #3 AWS IAM 설정 - AWS 음성지원 서비스를 활용한 신문 읽어주는 프로젝트 (0) | 2019.10.13 |
| #2 AWS DynamoDB설정 - AWS 음성지원 서비스를 활용한 신문 읽어주는 프로젝트 (0) | 2019.10.13 |
| #1 AWS 음성지원 서비스를 활용한 신문 읽어주는 프로젝트 (0) | 2019.10.13 |